

В этой заметке будут рассмотрены особенности алгоритма ГОСТ 28147-89 с точки зрения построения его эффективных реализаций. Мы обсудим несколько актуальных направлений в области оптимизации производительности ПО и покажем, что алгоритм ГОСТ 28147-89 обладает рядом весьма приятных для их применения особенностей.
В последние годы акцент в области оптимизации производительности программного обеспечения сместился в сторону активного использования параллельных вычислений. Это связано со снижением темпа роста тактовой частоты CPU: если раньше скорость программы увеличивалась независимо от разработчика по причине постоянного роста вычислительной мощности CPU, ускорения обмена данными с памятью и периферией, то сейчас ответственность за увеличение скорости исполнения программ ложится в большей степени на программистов. Теперь для достижения максимальной производительности приложения программисты должны учитывать возможности параллелизма, доступные в целевой системе. К таким возможностям относятся:
- распараллеливание задачи между ядрами процессора;
- использование векторных расширений CPU;
- использование GPU.
Алгоритм ГОСТ 28147-89 оказывается весьма удобным с точки зрения повышения эффективности его реализации с помощью описанных выше возможностей. Нас будут интересовать, конечно же, те способы повышения эффективности реализаций, которые сущностно опираются на свойства самого алгоритма шифрования. Мы рассмотрим также вопрос о построении легковесных реализаций, так как для них при решении задач оптимизации ГОСТ 28147-89 полезным оказывается тот же набор свойств алгоритма, что и при использовании GPU и векторных расширений CPU.
ГОСТ 28147-89 и векторные расширения CPU
Говоря о параллельных вычислениях на одном компьютере, чаще всего имеют в виду одновременные вычисления на нескольких процессорах (или ядрах одного процессора). Но помимо этого существует также возможность параллельных вычислений в пределах одного ядра – это использование векторных инструкций.
Векторные инструкции позволяют производить несколько операций за один такт процессора, например, складывать сразу несколько чисел.

Возможность выполнения векторных операций в современных вычислительных системах на платформах x86/x64 обеспечивается специальными процессорными расширениями SSE и AVX. Эти расширения добавляют новые регистры длиной 128 и более бит, а также инструкции для работы с ними.
Покажем, как можно применить эти расширения для эффективной реализации алгоритма ГОСТ 28147-89 (описание некоторых идей использования данных расширений можно найти также в статье [5]).
Как известно, один раунд алгоритма ГОСТ 28147-89 состоит из сложения с ключом по модулю 2, восьми 4-х битовых узлов замены и циклического сдвига на 11 бит влево. Очевидно, что выигрыш в производительности за счет использования векторных инструкций можно получить, только обрабатывая несколько блоков за раз. Причем чем большее количество блоков будет обсчитываться одновременно, тем больший выигрыш в скорости мы получим. Размер блока в алгоритме ГОСТ 28147-89 равен 64 битам, но так как используется сеть Фейстеля, все ресурсоемкие преобразования производятся только над половиной блока, то есть над 32 битами данных. Эта особенность алгоритма позволяет нам, например, складывать с раундовым ключом или циклически сдвигать одновременно несколько блоков, используя один AVX-регистр.
Отдельного внимания заслуживают узлы замен. Дело в том, что в расширении AVX была добавлена команда VPSHUFB, которая копирует байты из регистра-источника в регистр-приемник в порядке, описанном в индексном регистре.

Если в регистр-источник записать таблицу замен, а в индексный регистр (в младшие полубайты) поместить обрабатываемые данные, то с помощью этой инструкции можно за один такт процессора сделать замену для 16 полубайт, что позволяет получить значительный выигрыш в скорости по сравнению с последовательным применением узлов замен.
Стоит отметить, что эффективное использование этой инструкции возможно только благодаря тому, что в алгоритме ГОСТ 28147-89 используются именно 4-битные узлы замен. Действительно, так как команда VPSHUFB использует только младшие 4 бита каждого байта индексного регистра, то и заменять мы можем соответственно только их. К тому же одна таблица замен для 4 бит имеет размер 24 · 4 = 64 бита, что позволяет в один 128-битный регистр поместить сразу две таблицы.
Теперь перейдем непосредственно к цифрам. На графиках ниже представлены результаты измерений скорости шифрования в режиме гаммирования (режима, который весьма часто используется в криптографических протоколах) в зависимости от числа потоков. Измерения производились на стендах №1, №2 и №3. Стенд №1 имитирует серверный компьютер, стенды №2 и №3 – обычные пользовательские компьютеры.
При реализации протоколов TLS и IPsec для контроля целостности данных используется имитовставка по алгоритму ГОСТ 28147-89, поэтому распространенной задачей при использовании этих протоколов является шифрование с одновременным вычислением имитовставки. Ниже представлен график зависимости скорости шифрования с одновременным вычислением имитовставки от количества потоков. На графике режим MultiPacket обозначает одновременную обработку нескольких пакетов, подробнее этот режим описан в документации на КриптоПро CSP.
ГОСТ и GPU
Рассматривая эффективные реализации криптографических алгоритмов, нельзя не упомянуть о таком направлении как GPGPU (General-purpose graphics processing units).
GPGPU – это техника использования графических процессоров в вычислениях общего характера, то есть не связанных с обработкой графики – например, в криптографии.
Рассмотрим, в чем же заключаются преимущества использования GPU для вычислений общего характера.
Во-первых, это количество ядер. Если центральные процессоры имеют в среднем от 2 до 16 ядер, то графические – от нескольких сотен до нескольких тысяч – например, графический процессор GeForce GTX 970 содержит 1664 ядра, а Radeon R9 295X2 – 5632.
Во-вторых, это назначение транзисторов. В центральном процессоре большая часть транзисторов используется для кэша и управления потоком исполнения, в то время как в графических процессорах большая часть транзисторов используется для вычислений.

В-третьих, это пропускная способность памяти, которая у графических процессоров в несколько раз больше. Для примера, при использовании процессора Intel Xeon E5-2670 и 4-х модулей оперативной памяти DDR3 пропускная способность памяти составляет примерно 80 Гб/с, в то время как пропускная способность памяти уже упоминавшихся графических процессоров GeForce GTX 970 и Radeon R9 295X2 составляет 224 и 680 Гб/с соответственно.
Чтобы объяснить, чем же хорош алгоритм ГОСТ 28147-89 для реализации на GPU, нужно сначала немного рассказать о принципе вычислений на GPU.
Не вдаваясь в подробности, любая программа на GPU содержит несколько основных шагов, изображенных на рисунке ниже.
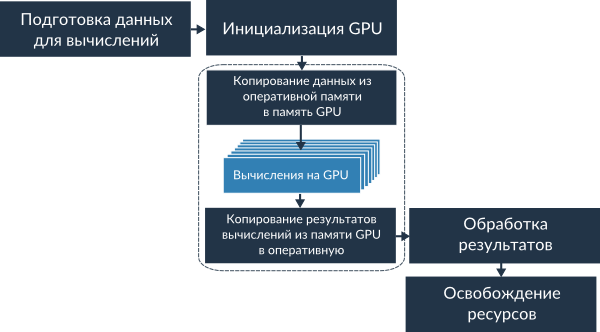
Данные на этапе вычислений на GPU обрабатываются в несколько тысяч потоков. Потоки выполняются не все одновременно, а группами. Во время работы одной такой группы все ресурсы графического процессора (векторные и скалярные регистры, память и т.п.) делятся между потоками этой группы, поэтому количество потоков в группе зависит от ресурсов используемых одним потоком для вычислений. Очевидно, что чем меньше ресурсов использует один поток, тем больше потоков может выполняться на GPU одновременно, а, следовательно, тем выше будет скорость работы программы.
Поэтому для достижения высокой скорости работы какого-либо алгоритма на GPU необходимо минимизировать количество ресурсов, используемых им для вычислений.
С этой точки зрения алгоритм ГОСТ 28147-89 имеет ряд преимуществ. Во-первых, это простая процедура получения раундовых ключей, которая не требует много ресурсов. Во-вторых, с помощью предвычисленной таблицы можно упростить раундовое преобразование. Таким образом, вместо восьми 4-битовых узлов замен и циклического сдвига мы имеем сложение по модулю 2 четырех элементов из предвычисленной таблицы. Все это значительно снижает количество аппаратных ресурсов, необходимых для работы алгоритма, и существенно увеличивает скорость его работы на GPU.

Другой способ оптимизации базового цикла алгоритма ГОСТ 28147–89 для GPU был предложен в работе [4]. Для уменьшения количества обращений к памяти автор предлагает реализовать таблицу замены через булеву функцию, что значительно повышает скорость работы алгоритма.
На графике ниже представлены результаты скорости шифрования на GPU для различных алгоритмов для построенной на основе данных идей реализации. Все измерения сделаны на тестовом стенде №2. Во время тестов в режиме простой замены шифровались данные размера 256 МБ и измерялась теоретическая и практическая производительность реализации алгоритма. Теоретическая производительность показывает скорость непосредственно шифрования на GPU, а практическая – скорость шифрования + копирования данных в память GPU и результатов из памяти GPU в оперативную. Реализации алгоритмов для OpenCL (кроме реализации ГОСТ 28147-89) взяты из открытого проекта engine-cuda.
Как видно из графика, практическая скорость шифрования на GPU слабо коррелирует с теоретической. Происходит это из-за того, что большую часть времени в реальных условиях занимают операции копирования данных из оперативной памяти в память GPU и обратно. Все это затрудняет использование GPU для шифрования на практике.
ГОСТ и легковесная криптография
В последнее время активно развивается такое направление, как легковесная (lightweight) криптография. Основная задача этого направления – это проектирование и реализация криптографических алгоритмов для устройств с небольшой вычислительной мощностью, таких как смарт-карты, сенсоры, RFID-метки. Реализации бывают аппаратные – это интегральные схемы (ASIC), и программные – это код для программируемых микроконтроллеров.
Основные цели легковесной криптографии – это минимизация ресурсов, необходимых для реализации алгоритма, при сохранении его стойкости и скорости работы. Под ресурсами подразумеваются размер устройства, потребляемая им мощность и его стоимость (в случае программной реализации это будут параметры используемого микроконтроллера). При таких условиях в большинстве случаев аппаратные реализации по всем параметрам превосходят программные, поэтому остановимся именно на них.
Проектирование легковесной аппаратной реализации по большей части заключается в нахождении оптимального баланса между всеми параметрами следующей схемы.
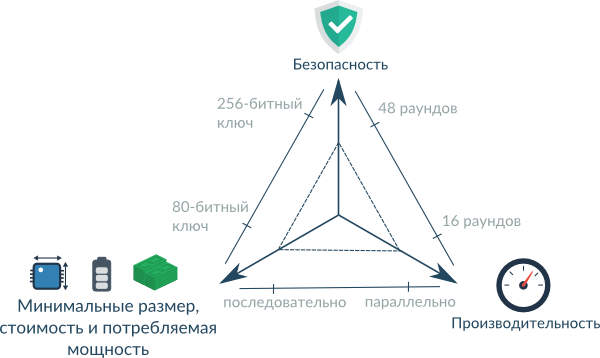
Параметры аппаратной реализации, то есть интегральной схемы, во многом определяются площадью, занимаемой схемой на кристалле кремния. Чем меньше площадь – тем меньше размеры и стоимость. Но эта величина сильно зависит от технологий, используемых производителем. Поэтому в качестве основной характеристики аппаратной реализации в легковесной криптографии используется gate equivalents (GE). Эта характеристика показывает, сколько элементов NAND ("И-НЕ") можно разместить на площади, занимаемой заданной схемой. Следовательно, чем меньше количество GE, тем меньше площадь схемы, а значит лучше ее параметры.
Теперь перейдем непосредственно к аппаратной легковесной реализации алгоритма ГОСТ 28147-89. Определяющим свойством алгоритма в данном случае является простая процедура получения раундовых ключей. Это свойство позволяет достичь хороших показателей аппаратной реализации. В работе [1] при использовании 8 одинаковых узлов замены из шифра PRESENT [2] достигается 650 GE и 800 GE при использовании таблицы замены TestParamSet.
Таким образом, для легковесной реализации ГОСТ 28147-89 полезным оказывается тот же набор свойств алгоритма, что и при использовании GPU и векторных расширений CPU. И этот набор свойств помогает добиться хороших параметров аппаратной реализации алгоритма таких, как маленький размер, малая потребляемая мощность и низкая стоимость. Все это позволяет эффективно использовать ГОСТ 28147-89 в смарт-картах, сенсорах, RFID-метках.
Подведем итоги
С точки зрения создания эффективных реализаций алгоритм ГОСТ 28147-89 обладает целым рядом преимуществ. Во-первых, это простое ключевое расписание. Во-вторых, это использование 4-битовых узлов замены, которые в программных реализациях хорошо осуществляются с помощью векторных инструкций, а в аппаратных требуют крайне мало ресурсов. И в-третьих, это простое раундовое преобразование в целом, которое хорошо ложится как на программные, так и на аппаратные реализации. При этом алгоритм до сих пор обладает колоссальным с точки зрения практики запасом прочности, о чем мы писали в нашей предыдущей статье. А с помощью небольшой модификации ключевого расписания, предложенной в работе [3, 6], можно исключить возможность осуществления даже теоретических атак (методы Исобе и Динура-Данкельмана-Шамира).
Приложение: Конфигурации тестовых стендов
Конфигурация тестового стенда №1
| Материнская плата | Supermicro, X9DR3-F, Версия BIOS American Megatrends Inc. 1.1, 03.10.2012 |
| Процессор | 2 ЦП Xeon(R) E5-2680 2.7 ГГц, Hyper-Threading включён, всего 32 логических процессора (семейство Sandy Bridge) |
| ОЗУ | 32 Гб |
| Жесткий диск | 256 Gb SSD |
| ОС | Windows Server 2008 R2 |
| Версия КриптоПро CSP | 3.6 R3 |
Конфигурация тестового стенда №2
| Материнская плата | Asus M5A99X Evo, версия BIOS American Megatrends Inc. 01.06.2011 |
| Процессор | QuadCore AMD FX-4100, 4154 MHz |
| Видеокарта | AMD Radeon HD 6970 |
| ОЗУ | 2 x 4Gb DDR3 1333 MHz |
| Жесткий диск | Non-SSD 1TB |
| ОС | Windows 7 x64 |
| Версия КриптоПро CSP | 4.0 |
Конфигурация тестового стенда №3
| Компьютер | MacBook Pro 17" начало 2011 |
| Процессор | Core i7, 2.3 ГГц, Hyper-Threading включён, всего 8 логических процессора (семейство Sandy Bridge) |
| ОЗУ | 8 Гб |
| Жесткий диск | 512 Гб SSD |
| ОС | Mac OS X Lion 10.7.5 |
| Версия КриптоПро CSP | 3.6 R3 |
Литература
[1] Poschmann, A., Ling, S., Wang, H.: 256 bit standardized crypto for 650 GE – GOSTrevisited. In: Mangard, S., Standaert, F.-X. (eds.) CHES 2010. LNCS, vol. 6225,pp. 219–233. Springer, Heidelberg (2010)
[2] Bogdanov, A., Leander, G., Knudsen, L., Paar, C., Poschmann, A., Robshaw, M.,Seurin, Y., Vikkelsoe, C.: PRESENT - An Ultra-Lightweight Block Cipher. In:Paillier, P., Verbauwhede, I. (eds.) CHES 2007. LNCS, vol. 4727, pp. 450–466.Springer, Heidelberg (2007)
[3] Дмух А.А., Маршалко Г.Б. О возможности модификации алгоритма шифрования ГОСТ 28147-89 с сохранением приемлемых эксплуатационных характеристик. Материалы XV международной конференции "РусКрипто'2013".
[4] Кролевецкий А.В.: Эффективная реализация алгоритма ГОСТ 28147-89 с помощью технологии GPGPU. Материалы XVI международной конференции "РусКрипто'2014".
[5] Достигаем феноменальной скорости на примере шифрования ГОСТ 28147—89. Журнал "Хакер". https://xakep.ru/2013/10/19/shifrovanie-gost-28147-89/
[6] A. A. Dmukh, D. M. Dygin, G. B. Marshalko, “A lightweight-friendly modification of GOST block cipher”, Матем. вопр. криптогр., 5:2 (2014), 47–55
Смышляев С.В., к.ф.-м.н.,
начальник отдела защиты информации
ООО "КРИПТО-ПРО"
Алексеев Е.К., к.ф.-м.н.,
ведущий инженер-аналитик
ООО "КРИПТО-ПРО"
Прохоров А.С.,
инженер-аналитик 2 категории
ООО "КРИПТО-ПРО"